
Здесь я пишу о том, что мне интересно
Всегда в топе
· профессиональный аудит сайтов
· продвижение проектов любой сложности
· консультации по всем этапам продвижения
· блокады сайта фильтрами поиска
· стратегии непоискового продвижения
· создание компаний контекстной рекламы
· корпоративные аккаунты в соцсетях
· вывод сайтов из под ручных санкций Google
· вывод сайтов из под санкций Яндекс
· гарантированное удаление любых ссылок
· индивидуальные консультации
май 05, 2010, 13:48
Откуда яндекс берет информацию для сниппета.
Даже начинающий оптимизатор знает, насколько велико значение сниппета в процессе позиционирования сайта в выдаче ПС.
Идеальный сниппет в слабоконкурентной тематике должен содержать как минимум одно вхождение поискового запроса, или его словоформы.

В ВК тематиках число вхождение колеблется от двух до четырёх.
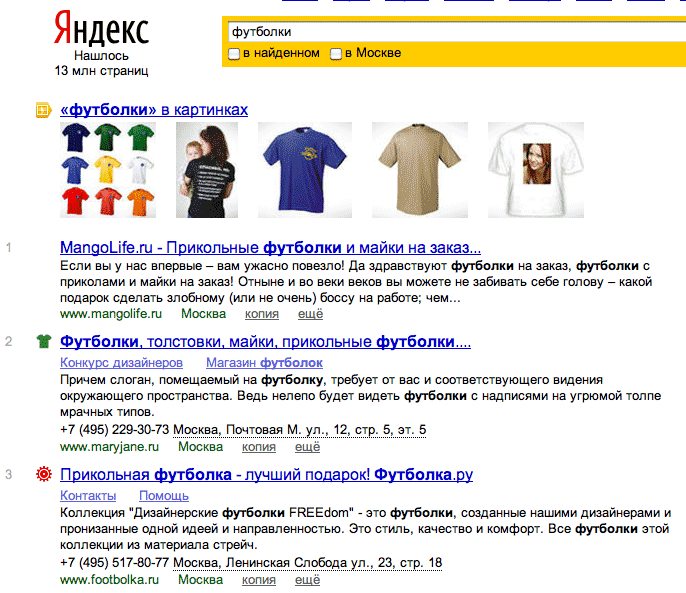
В нормальной ситуации, сниппет формируется из значимых для Яндекса html-тэгов позиционируемой страницы:
li, a, p, pre (тэги расположены в порядке убывания их значимости). Поэтому, необходимо позаботиться, чтобы на Вашей странице как минимум, были эти тэги; как максимум - содержали поисковые запросы и имели размер, необходимый для формирования текстовой аннотации страницы.
Экстремальные ситуации выглядят так:
- сниппет сформирован из меню сайта (тэги ссылки a - причина как правило недостаточное количество валидного релевантного текста на странице)
- сниппет сформирован из тэга метаданных description (контент расположен во фреймах, или отсутствует)
- НПС (найден по ссылке, контент такой страницы не может быть отранжирован по указанной в ссылке ключевой фразе)
Алгоритм построения аннотаций основан на вычислении сразу нескольких признаков, и последующей лексикографической сортировке предложений по совокупности таких признаков.
Чтобы понять принцип сортировки, нужно ввести термин опорной пары, ее позиции в предложении и ширины опорной пары.
Для простых, однословных поисковых запросов под парой понимается единственное слово пересечения (для предложений, в которых нет слов запроса, опорную пару определить нельзя). Под шириной опорной пары нужно понимать минимальное расстояние между словами опорной пары в предложении. Для однословных кивордов значение ширины опорной пары равно средней длине предложения русского языка (10 слов).
Позиция опорной пары - это позиция первого слова первой от начала предложения опорной пары минимальной ширины.
Сортировка предложений происходит по функционально однородной области документа (меню, область контента, новостной блок, заголовок раздела и так далее). Причем документ разделяется на информационные (область релевантного валидного контента) и служебные (меню, списки) сегменты.
Все шесть признаков сортировки выражаются в дискретных математических функциях, если Вы способны переварить это, вот ссылка на источник: (pdf, page 165). Приоритет признаков - от последнего, к первому.
Сниппет строится следующим образом:
- берется первое предложение после сортировки (отметим для себя, что очень важно начинать абзац Вашей страницы предложением с ключевым словом). Если это предложение по числу символов помещается в сниппет, то он добавляется туда. В противном случае он будет обрезан до длины в 150 символов;
- все словоформы киворда предложения добавляются в словарь использованных лемм;
- определяется, путем сортировки по сегменту, какие леммы не вошли в словарь, и предложения пересортируются по убыванию сумм слов запроса, не вошедших в первое предложение (важно: в Вашем абзаце должно быть как минимум два предложения, куда входит поисковый запрос или его словоформа);
- к полученному тексту добавляются предложения (обрезанные до 150 символов) до тех пор, пока предложение помещается в разрешенную максимальную длину текста сниппета. При этом алгоритм пропускает предложение, где разность плотностей ключевого слова меньше 1/4 - это позволяет избежать добавления предложений, содержащих только те слова запроса, которые уже вошли в сниппет (важно: используйте короткие предложения без перечислений).
- предложения, попавшие в предварительный сниппет, сортируются в соответствии с порядком, с которым они шли в исходном документе. Если какие-нибудь два подряд идущих предложения аннотации не являются соседними в тексте документа, то они отделяются многоточием в тексте аннотации.
Вуаля! Наш сниппет готов...
Не стоит думать, что сниппет постоянен от апа к апу! Управляйте релевантностью Вашего сниппета, добавляя и исключая словоформы и чистые вхождения ключевого поискового запроса в сегменты кода, из которого он сформирован!
Остались вопросы по сниппетам? Приглашаю на индивидуальную консультацию
